
Towards Hexagonal Architecture - Interface Segregation
After examining driven ports for data-access separation and dependency inversion, I will take a closer look at interface segregation, ports on the driver side, and port naming.

In the last article, I showed how to introduce ports on the “driven” (right) side of the hexagon to effectively invert the dependencies between data-access and business concerns, such that the first depends on the latter completely and there is no data-access reference anymore in the business application service. The following diagram illustrates the code’s current structure:
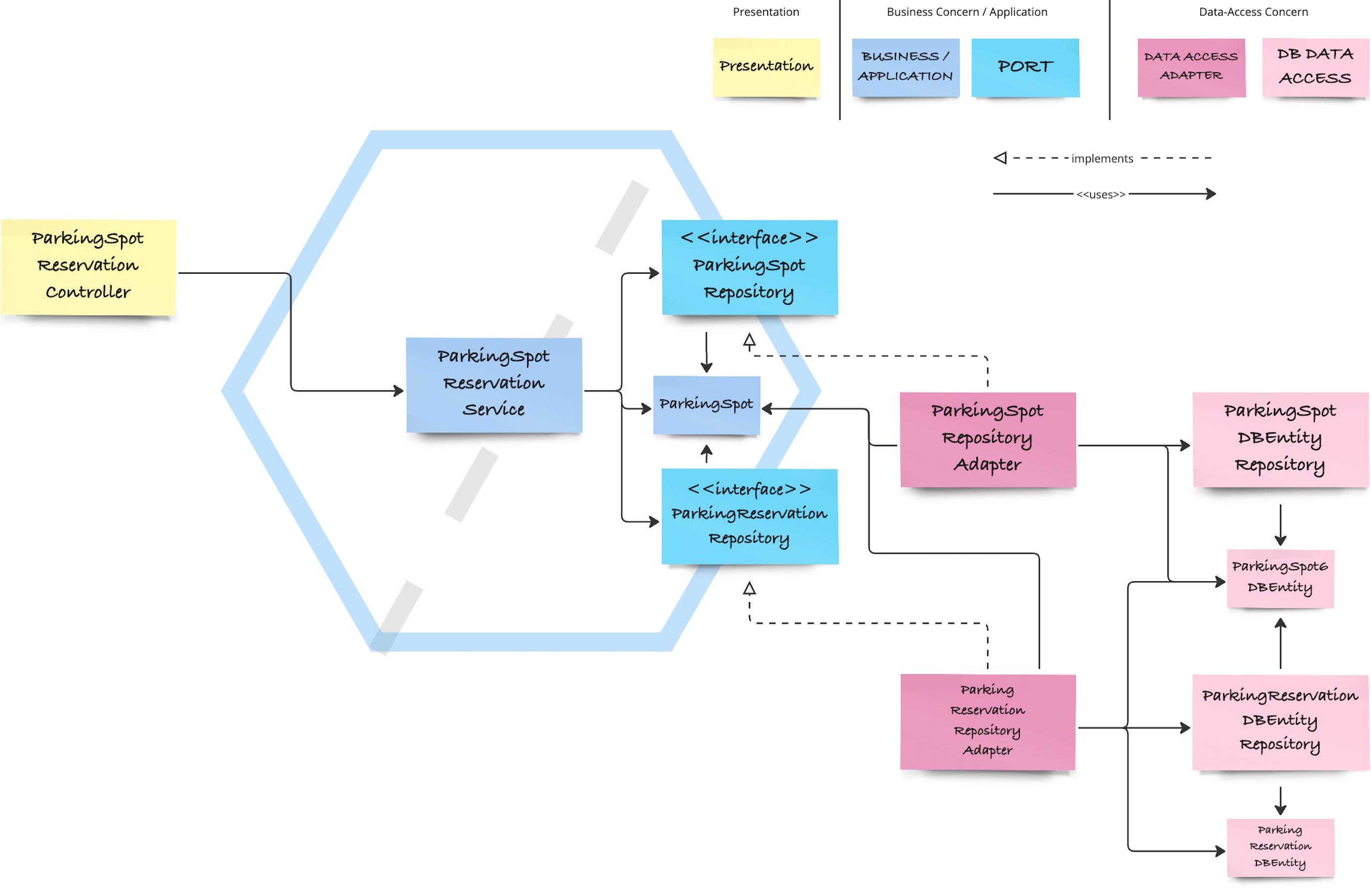
The “driven” side, which is called that way because it is driven by the application service as indicated by the vertical line inside the hexagon, now obeys the rules of Ports and Adapters. But are there still adaptations needed to be able to talk of a real “hexagonal architecture”?
Interface Segregation Port on the Presentation Side
Indeed, if we look at the “driving” side, meaning the left side of the diagonal in the diagram from where the application is called, we can see that there is still a direct dependency from the controller to the application service.
This is not perfect as the application service may expose various public use-case methods that the controller doesn’t need to know about.
However, especially during transition phases from a technical service with multiple use-case methods to a cleaner, business-centric structure, it is advisable to first logically split the service into individual use-case methods and then step-by-step split it up physically into smaller services.
This can be achieved by employing interface segregation and using these interfaces in place of the actual service within the controller, reminiscent of the strangler-fig pattern. The controller won’t need to know that behind the scenes, it is actually using a large service. This makes the controller also easier to test, as only one method needs to be stubbed and not an entire service with many methods.
The resulting structure looks as follows:
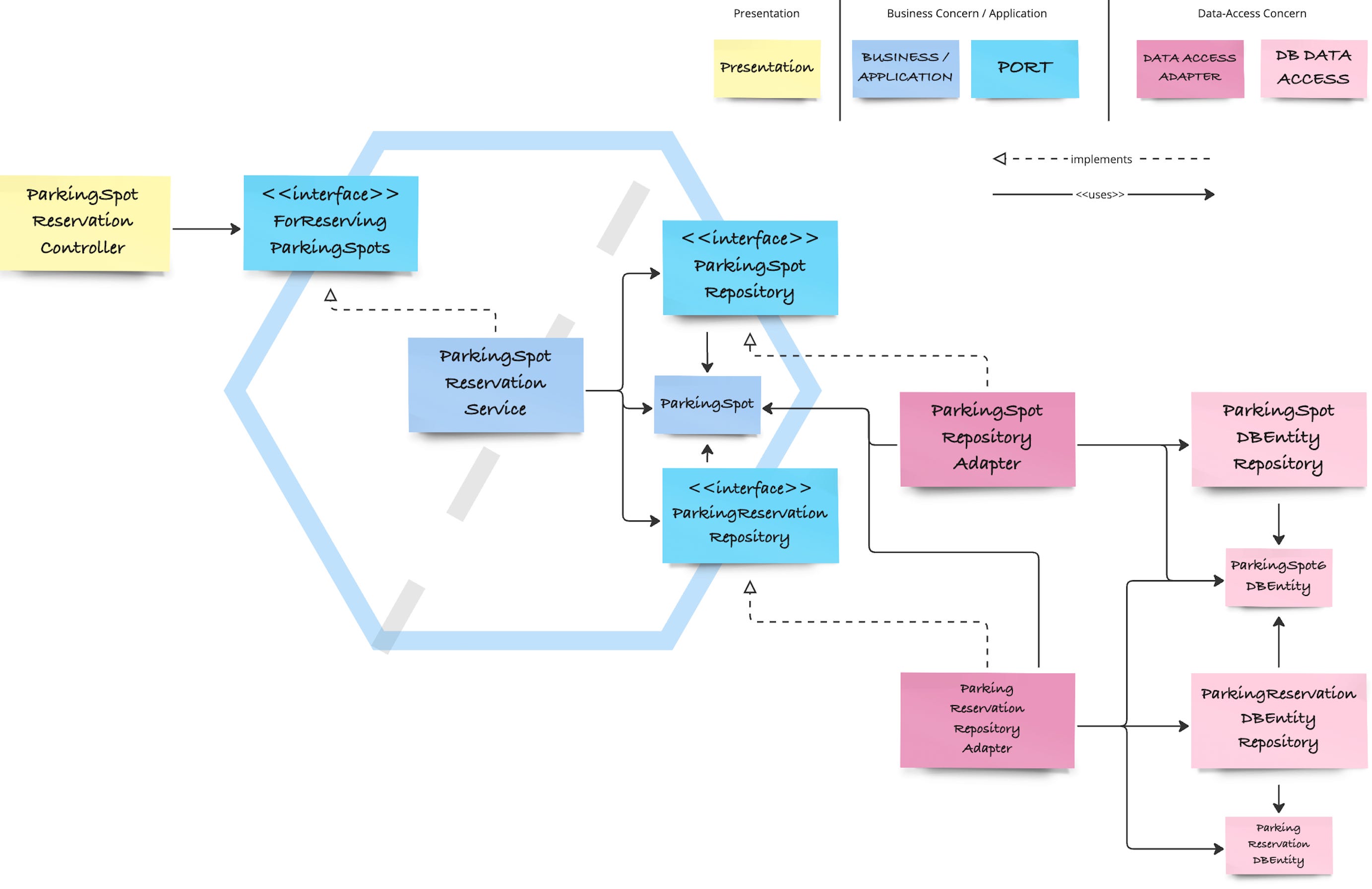
Importantly, this interface or port only contains either primitive- or application-specific data structures and no data structures or annotations of the presentation concern (i.e. DTO representations of JSON, XML, etc.) anymore.
This driving port on the left side of the diagonal in the diagram is used by the controller and implemented by the application service, which is different from the ports on the right side of the diagonal, which are used by the application service, and implemented by the data-access adapters.
Thus, the controller effectively becomes the adapter between presentation and application concerns as it adapts the JSON DTO to a representation prescribed by the application service.
Naming Ports
In the diagram, we should treat 1 edge of the hexagon as 1 port, and each port is for doing something. So we should always ask ourselves: what is this port for?
I prefer to name port interfaces according to the action that they perform. Thus, a possible name could be “ForReservingParkingSpots”. Alternatively, “ReserveParkingSpot” would also serve the purpose of illustrating such an action.
I would avoid naming these segregated interfaces with only 1 method signature with a noun, because only their implementations typically represent objects that are nouns, as they often implement multiple different port interfaces or represent a real-world concept like ReserveParkingSpotUseCase.
Interface Segregation on the Repository Side?
If we move our attention again to the driven side of the hexagon, we can see that this naming rule is actually not applied yet. We use “repository” in the name for both ports.
From a ports and adapters perspective, we can also split these two repository interfaces into single ports that only contain one public method signature each.
This approach can have several advantages, e.g.
Each port can have another implementation, e.g. if queries and commands use different endpoints.
Multiple ports can be implemented by one repository, but the application service / hexagon only needs to know about the methods it actually requires.
Using stubs and fakes in unit tests is simplified, making it easier to apply Outside-In Test-Driven Development where we focus on the interfaces the application interacts with instead of their implementation.
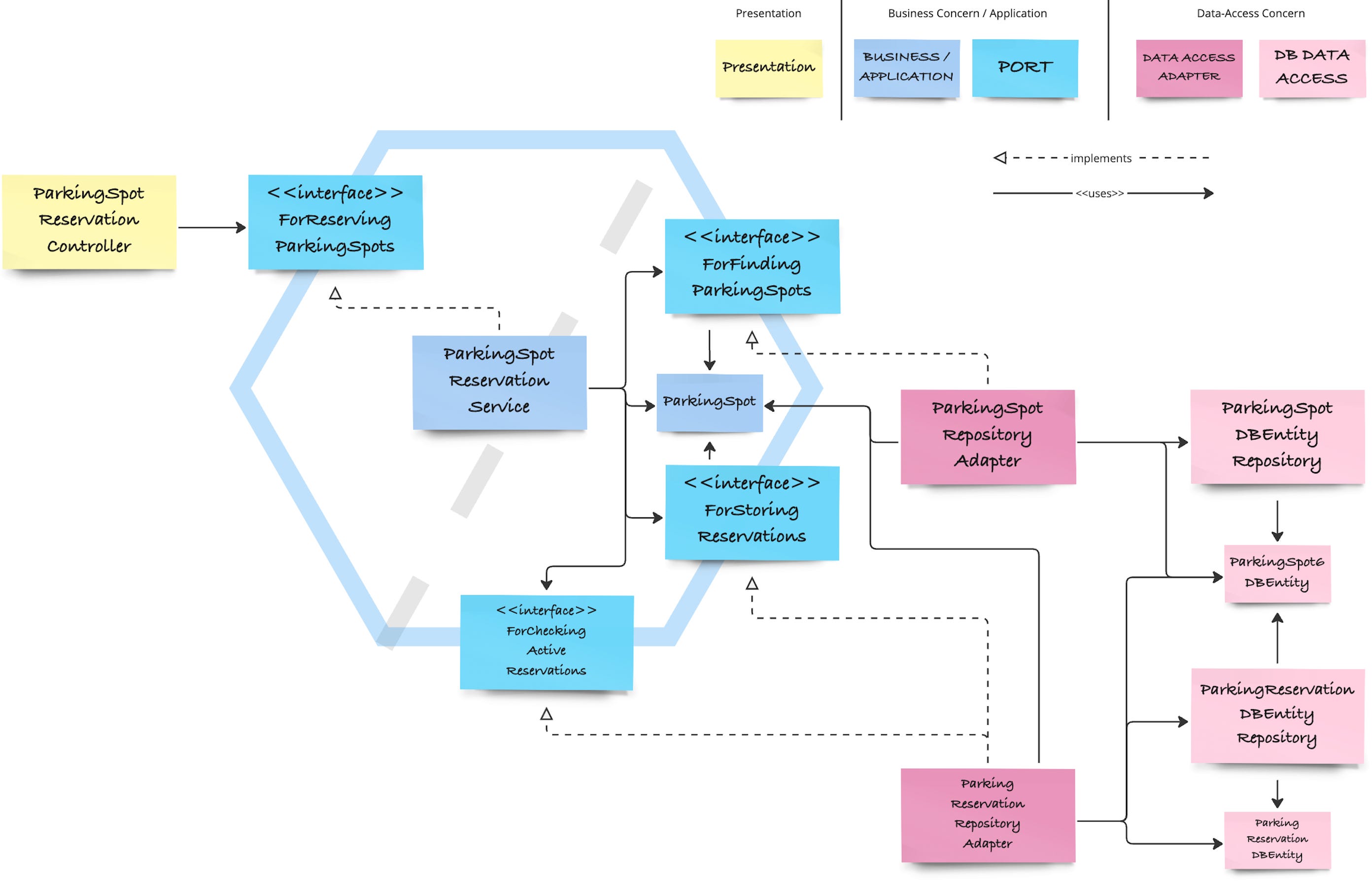
In practice, it is usually rather inconvenient to separate CRUD repository interfaces into several single-method ports as the user of these interfaces often expects to find these methods in the same place according to the repository pattern.
This is why I would only split them up if there is a reason for it. On the other hand, if we use a modern IDE, extracting or inlining an interface is trivial, so we can also play around with different designs and decide on a case-by-case basis.
To name these ports we can ask again “what is this port for?”. Reasonable names could be “ForCheckingActiveReservations”, “ForStoringReservations”, or “ForFindingParkingSpots”, or simply their action names “CheckActiveReservations”, “StoreReservation”, “FindParkingSpots”.
Thinking about ports that way without considering how they are implemented eventually lets us focus much more on what needs to be accomplished by the application from a business perspective rather than how we store the data, a key consideration also when we want to add additional concepts on top of hexagonal architecture, like Clean Architecture or Domain-Driven Design Tactical Patterns.
Ports Location
As a reminder, both inbound and outbound ports are defined in the application / service concern. However, they are used (inbound ports) or implemented (outbound ports) by the respective presentation- or data-access concern class, which are located outside the application concern.
Conclusion
Interface segregation, one of the 5 SOLID principles, can help us focus an application on the actions it needs to perform, meaning its behaviours, rather than the technologies and patterns used to perform these actions.
It achieves this by ensuring ports only contain one (or a few) method signature(s) with a specific, actionable name each like “ForStoringReservations” or “StoreReservation” instead of generic noun-based names that are magnets for all kind of unrelated method calls.
However, keep in mind that having a large number of one-method interfaces can be cumbersome to work with as well, so combining related interfaces into one (because they change for only one reason and together), e.g. for the sake of creating CRUD repository interfaces, can greatly enhance usability. Balance is key. There is no one size fits all, which is why you should be proficient in your IDE’s refactoring tools.
In the next article, I will have a look at how we can improve expressiveness by introducing concepts from Domain-Driven Design, so if you haven’t already, subscribe if you don’t want to miss it:
Resources
This article is part of a series moving towards a business-centric architectural design. See the following post to get started.
This series of articles is an addition to the From Layered to Hexagonal Architecture in 2 steps article.
We touch on the same topics in our O’Reilly course “DDD, EventStorming, and Clean Architecture”. Check it out to learn how to use Classic TDD to implement DDD Aggregates in Hexagonal and Clean Architecture.
If you want to learn more about effectively separating concerns, you could also have a look at our on-premise, remote or hybrid workshop Modern Software Architecture Design Patterns.
Hello, in the video why use instance of, wouldn't it be better to have multiple catches?