
Kafka Is Not a Global Variable
How I use Kafka in an event-driven, domain-driven distributed system - and what I avoid.

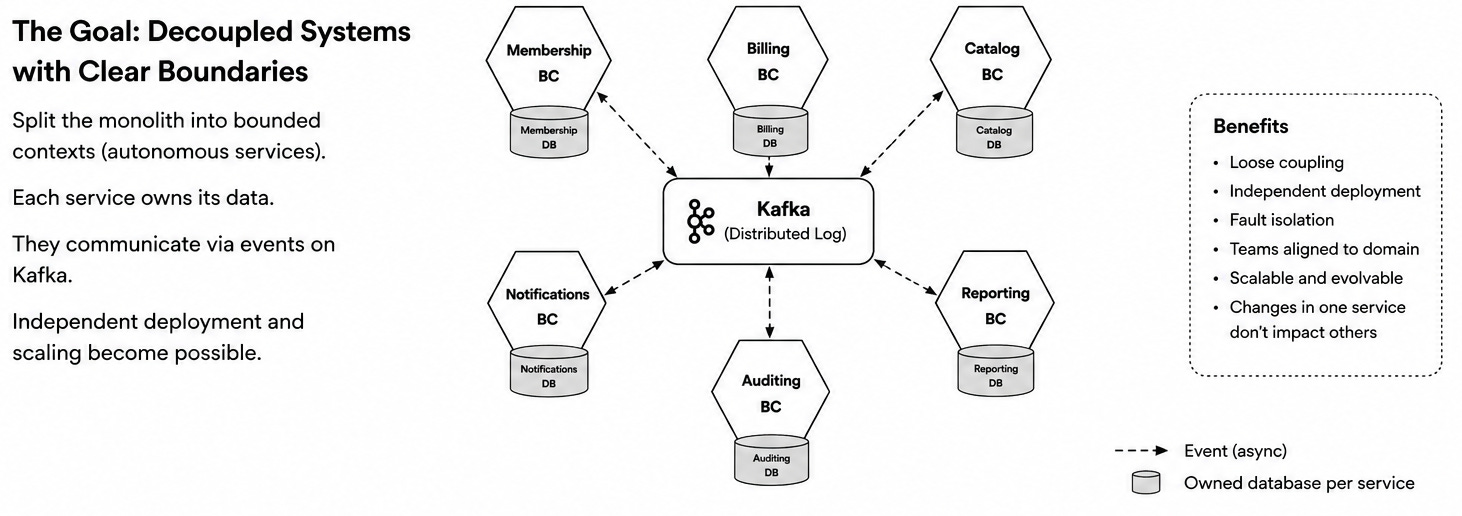
Event-driven architecture is often introduced as an antidote to tightly coupled systems. Instead of one service asking five other services for data at runtime, services publish events. Other services react independently. Coupling seems to decrease, which we can see in the diagrams below.
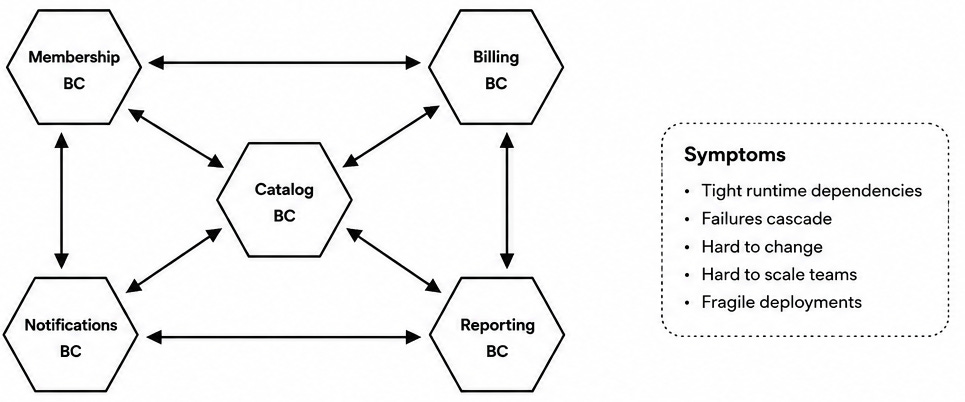
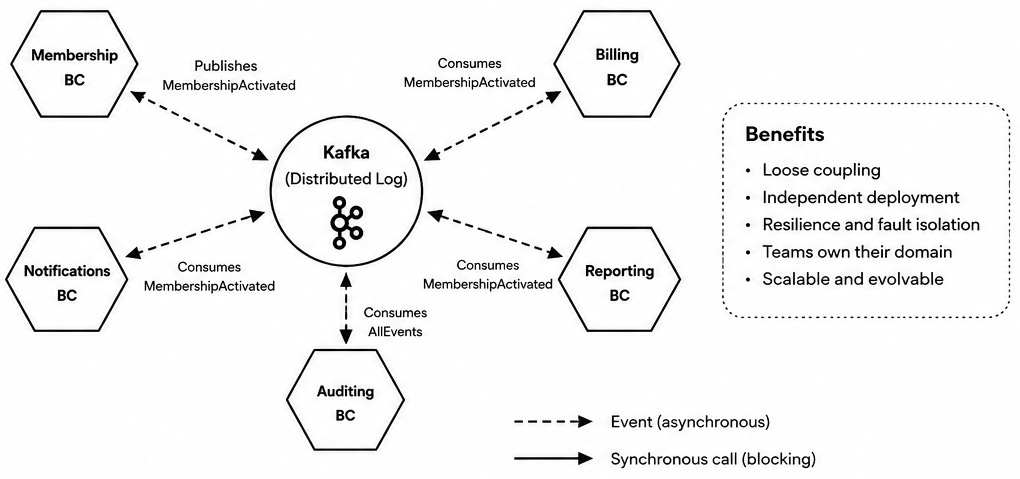
But then, a new problem appears:
We treat Kafka like a global variable.
Every service publishes whatever it knows to Kafka topics. Every other service consumes whatever topic it can get its hands on. This way, topics become a shared pool of facts, semi-facts, technical notifications, and accidental implementation details. Over time, teams stop asking:
Which bounded context owns this fact?
Who actually needs to know it?
Is this a stable public contract?
They ask only:
Can we put it on (or get it from) Kafka?
That is how an event-driven system begins to recreate an old architectural mistake in a new form…
An Old Anti-Pattern Re-Appears: A Shared DB
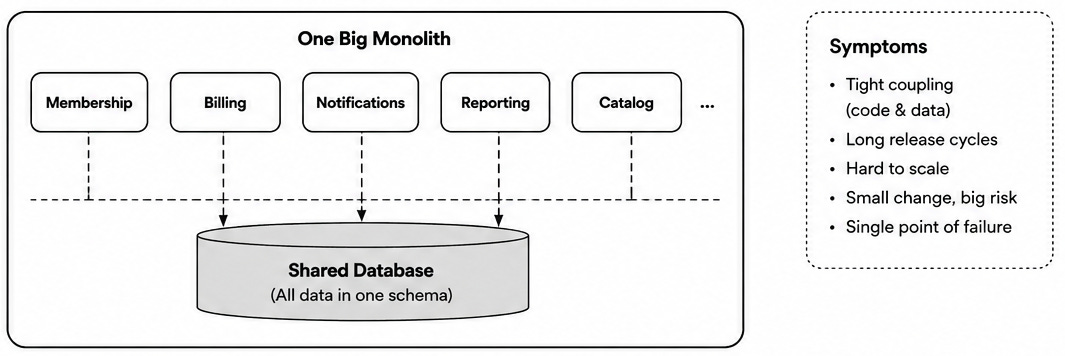
For decades, many organisations built systems around a shared database. The database became the place where everyone looked for truth.
At first, that felt efficient:
data was easy to access,
reporting was convenient,
new features could reuse existing tables.
But the cost appeared later. Teams became coupled to schemas they did not own. Internal implementation details turned into public dependencies. Changing a table meant coordinating with half the organisation.
We understood that this was a bad idea.
A shared database does not merely store data. It quietly shapes ownership, boundaries, and changeability.
The New Risk: Repeating that Pattern with Kafka
Kafka is not a database in the traditional sense. It is a distributed log. This distinction is important.
A log is append-only. It records facts that happened. Consumers can read those facts at their own pace, build projections, and derive local state without calling the producer synchronously, effectively decreasing coupling.
That is incredibly useful.
But if we treat Kafka as the default place for every system fact, we risk creating another shared dependency layer. The mechanism is different, but the organisational effect can become familiar:
internal details become external dependencies,
consumers bind themselves to facts they do not truly need,
architectural boundaries blur,
Kafka becomes the central place where everyone expects everything to be available.
That is not decoupling. It is coupling through a different medium.
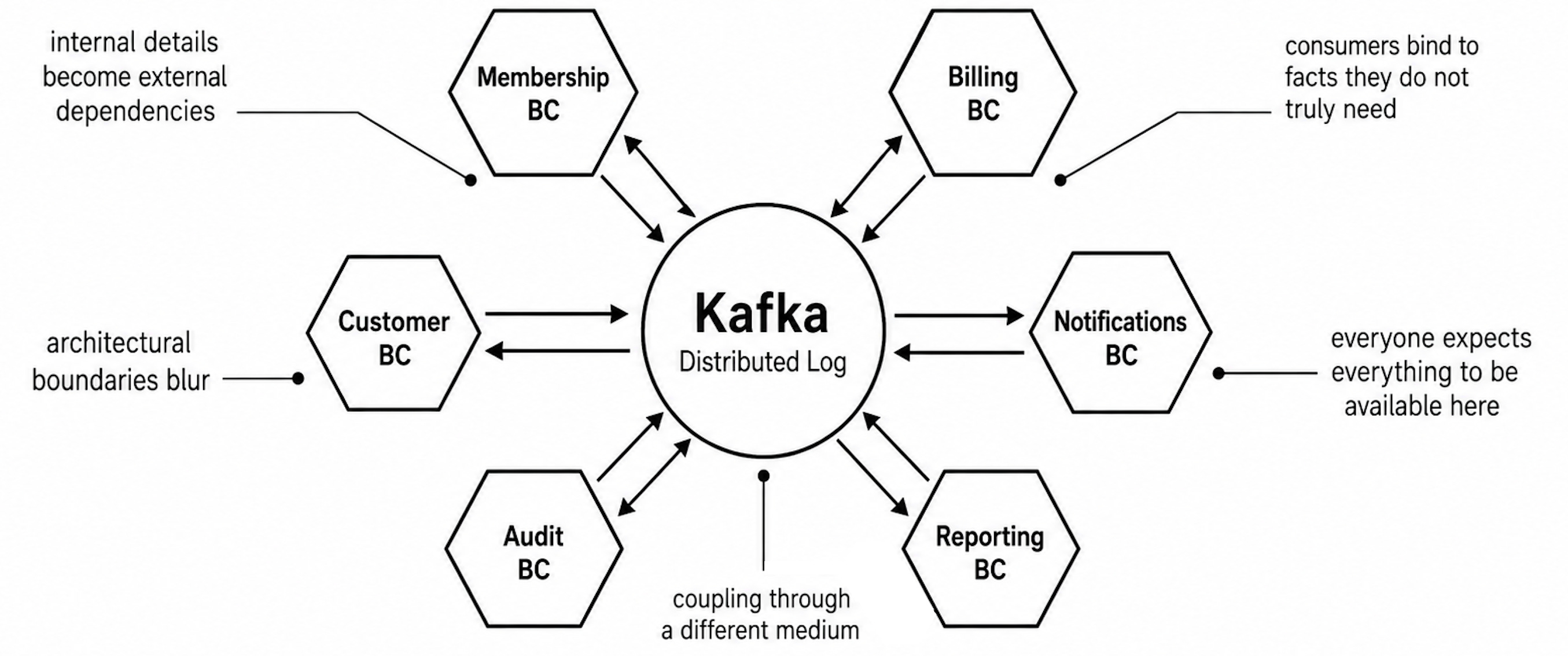
A Better Interpretation: Kafka as an Organisational Log
Kafka becomes powerful when we use it more intentionally:
Kafka should contain facts that are relevant beyond one bounded context.
These are integration events: published business facts that other bounded contexts, reporting systems, or organisation-wide concerns may reasonably care about.
Examples might include:
CustomerRegisteredMembershipActivatedInvoicePaidContractCancelled
These facts are not merely private implementation details of one bounded context. They are meaningful enough that another part of the organisation may depend on them.
That does not mean every internal event belongs on Kafka.
Inside a bounded context, a model may use more fine-grained domain events:
EligibilityConfirmedMembershipTermsCalculatedActivationApprovedMembershipActivated
Only the final fact, or perhaps a carefully chosen subset of those facts, may deserve to become an external integration event.
Bounded Contexts Still Own Their Models
A bounded context should remain responsible for its own:
ubiquitous language,
business rules and invariants,
internal state,
and internal domain events.
Kafka should not decide any of that.
A bounded context may:
consume integration events published by others,
react to them locally,
change its own state according to its own rules,
and publish new integration events when other contexts or the wider organisation need to know what happened.
That is a very different mental model from “just put everything on Kafka.”
It preserves ownership, autonomy, and the reason we introduced bounded contexts in the first place.
Publish Facts, Not Convenience
A useful test is this:
Would this event still deserve to exist if there were no current consumers for it?
For some events, the answer is yes. They may matter for:
auditability,
future integrations,
operational traceability,
regulatory needs,
or a broad organizational understanding of what happened.
For others, the answer is no. They exist only because one consumer currently wants to avoid an API call. That does not automatically make them worthy of an organisation-wide log.
This does not mean events need to be minimal. Event-carried state transfer can be the right choice. But the event should still represent a fact worth publishing, not simply a convenient data extraction mechanism.
The Principle
A concise way to state it is:
Kafka is not a global variable. It is a durable log of intentionally published organisational facts.
Or, in Domain-Driven Design terms:
Bounded contexts own their models. Kafka carries selected integration events across them.
That distinction prevents a subtle architectural slide:
from explicit contracts to accidental dependencies,
from autonomous services to shared semantics without ownership,
from event-driven design to event-shaped coupling.
Conclusion
Kafka is an excellent infrastructure for event-driven systems. But its value does not come from putting everything on it without a reason that justifies why we did it.
Its value comes from publishing the right things:
facts with meaning beyond one bounded context,
facts stable enough to become contracts,
facts the organisation benefits from retaining and distributing.
Used this way, Kafka does not replace or remove bounded contexts. It connects them.
It does not become a new shared database. It becomes a shared organisational memory of selected business facts.
Want to apply this to your architecture?
If your team is already using Kafka, event-driven architecture, or microservices, the hard part is often no longer the infrastructure. It is deciding which facts deserve to become public contracts, where bounded contexts begin and end, and how teams can collaborate without recreating a shared database in a new form.
Codeartify helps software teams work through exactly these questions in practical, hands-on formats:
A 15 mins free call to discuss where we could be of service in your Kafka-based system: codeartify.com/booking.
Not sure whether DDD fits your Kafka-based system? We offer a 3 hour decision workshop on exactly that topic: codeartify.com/decision-workshops.
Request a tailored in-house workshop for Kafka, DDD, EventStorming, bounded contexts, or event-driven architecture: codeartify.com/custom-workshop.
We also offer a ready-made workshop including Kafka, Kotlin/Java, DDD, and Axon: codeartify.com/event-sourcing
Download practical architecture resources, including cheat sheets on event-sourced DDD systems and AI Agent Skills: codeartify.com/downloads
Want to learn the basics of EventStorming and DDD? Checkout our O’Reilly e-learning course: codeartify.com/elearning
Kafka can connect bounded contexts. The design work is making sure it does not accidentally replace them.