
Adding Domain-Driven Design to Ports and Adapters - Rich Domain Model vs. DTOs
In this article, I will discuss what types of data structures exist and which ones should contain business logic contributing to a rich domain model and which should remain anaemic data structures.

In the previous article, I illustrated how we can increase expressiveness of ports by replacing low-level primitive types with higher-level, context- and domain-specific types.
However, these data structures initially simply wrap some co-dependent data and do not much else. If we want to improve the expressiveness of our software, we need to find logic that belongs to these data structures and move it closer to them.
A couple of questions regarding data structures need to be answered before we can start moving logic into classes, which I will discuss in the following:
Which data structures are pure data transfer objects (and thus, devoid of logic)?
Which data structures can contain logic?
Which data structures can be used in port interfaces?
Let’s focus on the highlighted classes in the diagram below:
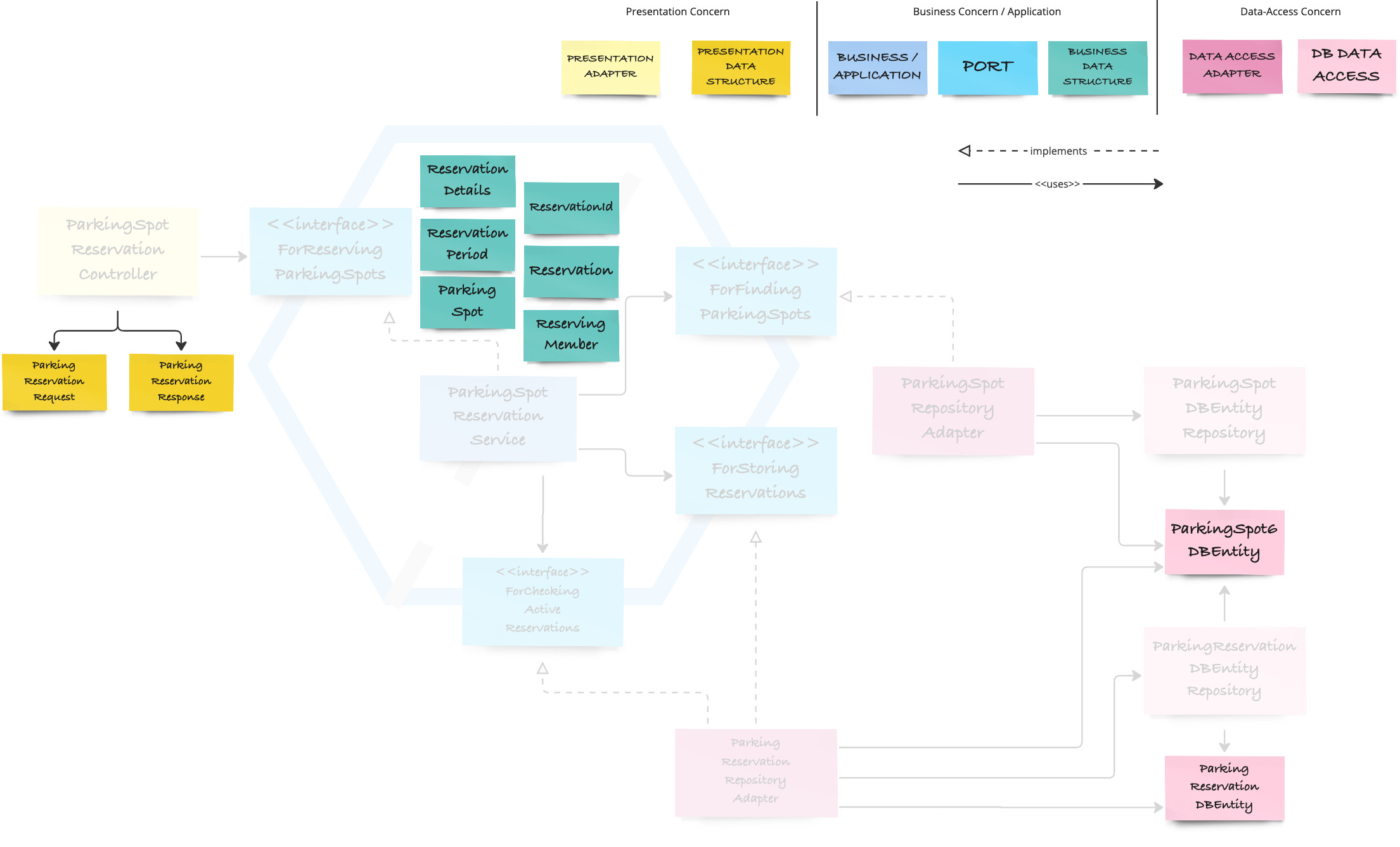
In the presentation concern, there are two classes ParkingReservationRequest and - Response.
Inside the hexagon, there are ReservationDetails, ReservationId, ReservationPeriod, Reservation, ParkingSpot, and ReservingMember.
In the data-access concern, there are ParkingSpotDBEntity and ParkingReservationDBEntity.
Which of these are pure DTOs, can contain logic, and can be used in port interfaces?
Pure Data Transfer Objects
Anything that represents pure data should not contain any logic at all.
Presentation-Concern Data Structures
ParkingReservationRequest and -Response are simply class representations of JSON data structures. Thus, these two classes should only contain getters, setters, and constructors, along with utility functions like hash code or equals and toString. No mapping or business logic should be part of these classes.
Data-Access-Concern Data Structures
The same logic applies to the data structures on the data-access side. Both ParkingReservationDBEntity and ParkingSpotDBEntity simply represent a database table row. They are not business entities and should not contain any business logic either, as this would entangle the two concerns.

Data with Logic - the Domain Model
What we often refer to as the domain model in Domain-Driven Design are actually the data structures used inside the core of the hexagon to achieve some business goal.
These data structures are magnets for business logic and should therefore be used exactly for that - building up a rich domain model with functionality on the classes that make sense in the specific domain they’re used.
In Domain-Driven Design, there are three domain model types:
Value Objects / Values
Entities
Aggregates
Value objects, or simply Values, are context-specific objects without an identity, like for example an ID, FirstName, or Dollar. If two objects have the same values, they are treated like they were the same. They contain business logic for validation, such that they are never in an invalid state, or formatting like a PhoneNumber that can be queried for a local or international format.
Entities, on the other hand, are objects that have an identity. Two entities with the same values are only the same if their identifier, for example an ID value object, are the same. Entities contain value objects or other entities.
Entities should also use value objects as internal fields. Primitive types should only be used when domain constraints aren’t required. When in doubt, it's better to introduce a value object and later discard it than to miss an important domain constraint.
Aggregates are entities that cluster other entities and value objects so that each aggregate can be treated as a whole. Aggregates provide a transactional boundary to avoid inconsistent states. Any change to any of the internal entities can only be done through the aggregate’s methods and the internal entities should never be exposed and manipulated outside of their aggregate.
In the context, the domain model could look as follows:
ReservationDetails, -Id, -Period, and ReservingMember are value objects.
ParkingSpot would be an entity or an aggregate, but because it is currently just an ID, we could rename it to ParkingSpotId and consider it a value object as well.
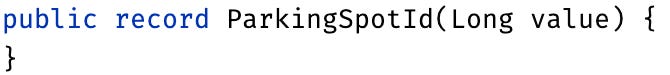
The only aggregate we can see here is Reservation, but it currently lacks a dedicated ID every aggregate should be assigned when it’s created. Currently, ReservationId is only created when the Reservation aggregate is stored. Such an ID is tied to persistence concerns rather than the domain model. In a future article, we will replace it with a domain-specific, independent ID. If you don’t want to miss the article where I will do that, simply subscribe here:
Of course, once we start refactoring the logic, we may notice that some definitions change and a value becomes an entity or the other way round. The current preliminary domain model could look as follows:
Data Structures in Port Interfaces
Even though we could imagine having special DTOs to transfer data between the outside world and the core, which do not expose the internal domain model, in practice, too many translation steps can become cumbersome to maintain and even start to slow down the application significantly.
Translation should be minimal such that the core is isolated from the surrounding world, but exposing certain internal structures of the domain model in the port interface does not hurt this isolation as long as we keep some rules in mind.
Let’s see which domain model classes are unproblematic to expose in port interfaces and which should be avoided under some conditions.
Inbound Port Interfaces
The transactional-boundary property of aggregates has profound consequences to what data structures can be used in inbound port interfaces:
Never expose Aggregates in inbound ports!
If we expose aggregates in inbound ports, they are outside the transactional boundaries of that port interface. Thus, changing their state outside may have unforeseeable effects, leading to strange and hard to find defects and data inconsistencies.
On the other hand, value objects pose no problem as they are simply enhanced data structures that are always in a valid state.
This has advantages because no invalid data structure can be passed into or out of the hexagon. Conclusively, we can use Value Objects in inbound port interfaces instead of unvalidated primitive types.

Outbound Port Interfaces
Outbound port interfaces behave differently than inbound ports. They are used always within the transactional boundaries of the hexagon. Aggregates are “data storage units”. Even though they are not part of the data-access concern, they should only be used in CRUD repository interfaces that are used to store and retrieve aggregates.
It could be tempting to use aggregates for other purposes, e.g. if we want to send a message that requires some or all of the aggregate’s data. However, aggregates are only safe for repository ports but should not be used in outbound messaging to prevent unintended side effects when consumed by unknown adapters. Instead, we should create a dedicated value object for such cases.
Such an uni-directional messaging port could be seen similarly to the return value of the inbound port. We don’t want to expose the internal domain model to anybody else than the dedicated repository adapters and the application-specific service class to avoid unintentional, uncontrollable changes in our data.
Value objects, on the other hand, can and should be used in all ports. Also a dedicated message object can contain the same value objects as the aggregate.
On the other hand, never expose non-aggregate entities. Neither in inbound- nor in outbound ports. They are protected by the aggregate they belong to and should only be changed using aggregate methods to ensure data integrity.

Exposing the Domain Model?
Some may argue that exposing the domain model to the outside world harms encapsulation. This is absolutely true. To circumvent that, we can still create dedicated, application-concern-specific DTOs and use them in our inbound and outbound port interfaces if that makes sense. Or simply use primitive types again.
We always need to weigh the additional translation / mapping overhead against a more isolated core. As soon as we expose the core domain model in our ports, we give away some of the freedom of changing it independently from the outside world.
If the core is only used by our team, we may choose such a more relaxed approach. On the other hand, if other teams want to integrate our core as a library, we may hide away the entire internal model and instead pass a simple data structure with primitive types and validate them within. It depends on your context which way you choose.
Conclusion
I have now illustrated which data structures can contain logic and which not. Furthermore, I showed which of them can be used in which port type.
If we want to employ a Domain-Driven Design domain model in our core, we should only expose value objects in the inbound port interfaces.
On the other hand, outbound CRUD repository ports called from within the hexagon can contain both values and aggregates as the transactional boundary is defined around the inbound port interface, shielding the aggregate from dangerous operations that could lead to data inconsistencies. However, aggregates should not be used in non-repository ports to avoid unintentional aggregate manipulation in these adapters.
Entities should neither be used in inbound- nor outbound ports as they need to be part of an aggregate and only be manipulated using methods defined on that aggregate.
Now that we know which entities can be used to move logic towards, in the next article I will show how to identify it in code and move it towards the various values and aggregates to build up a rich domain model.
Resources
This article is part of a series moving towards a business-centric architectural design. See the following post to get started.
This series of articles is an addition to the From Layered to Hexagonal Architecture in 2 steps article.
We touch on the same topics in our O’Reilly course “DDD, EventStorming, and Clean Architecture”. Check it out to learn how to use Classic TDD to implement DDD Aggregates in Hexagonal and Clean Architecture.
If you want to learn more about effectively separating concerns, you could also have a look at our on-premise, remote or hybrid workshop Modern Software Architecture Design Patterns.
What tool do you use for drawing?
Thanks for the perfect series. Waiting for the next one.