
Ports & Adapters-Style Architectures: Ditching the Dogma for Pragmatism
Avoid unmaintainable software due to Ports & Adapters-style architectures by separating the advantageous from the optional on a per-use-case basis.

Ports & Adapters Under Fire
Recently, I got the impression that Ports & Adapters (PA)-style codebase structures have come under a lot of pressure. Reasons may be the various definitions found on the internet that make it hard to know which one to follow; the many port abstraction interfaces and associated mappings between core and outside world; or the class explosion per folder if the entire system only contains one core, data access, and presentation folder without further structuring into bounded contexts, “features”, or use cases.
Whatever the exact reason, in this article, I discuss what I think are elements of PA-style architectures that can be left out and on the other hand what elements are really advantageous to avoid unnecessary coupling to code and data that is not under our control.
It’s probably not conclusive so if you want to discuss further topics, just ask it in the chat :) Let’s get started!
If you want to get started on Hexagonal Architecture, check out my first blog post here:

Lose the Ports
A key problem with PA-style architectures is that they inherently come with what may feel like unnecessary abstractions - the ports themselves!
A port is a method signature that exposes either primitive data types or data structures from within. Such an approach essentially leads the “outside” of the hexagon to depend on the core of it, not the other way round.
Are these port interfaces actually needed? Not necessarily. The main idea is that the methods of the core hexagon don’t expose any outside data structures. If we simply follow this guideline and adhere to the dependency inversion principle, we don’t need port interfaces and instead can use the actual implementation directly.
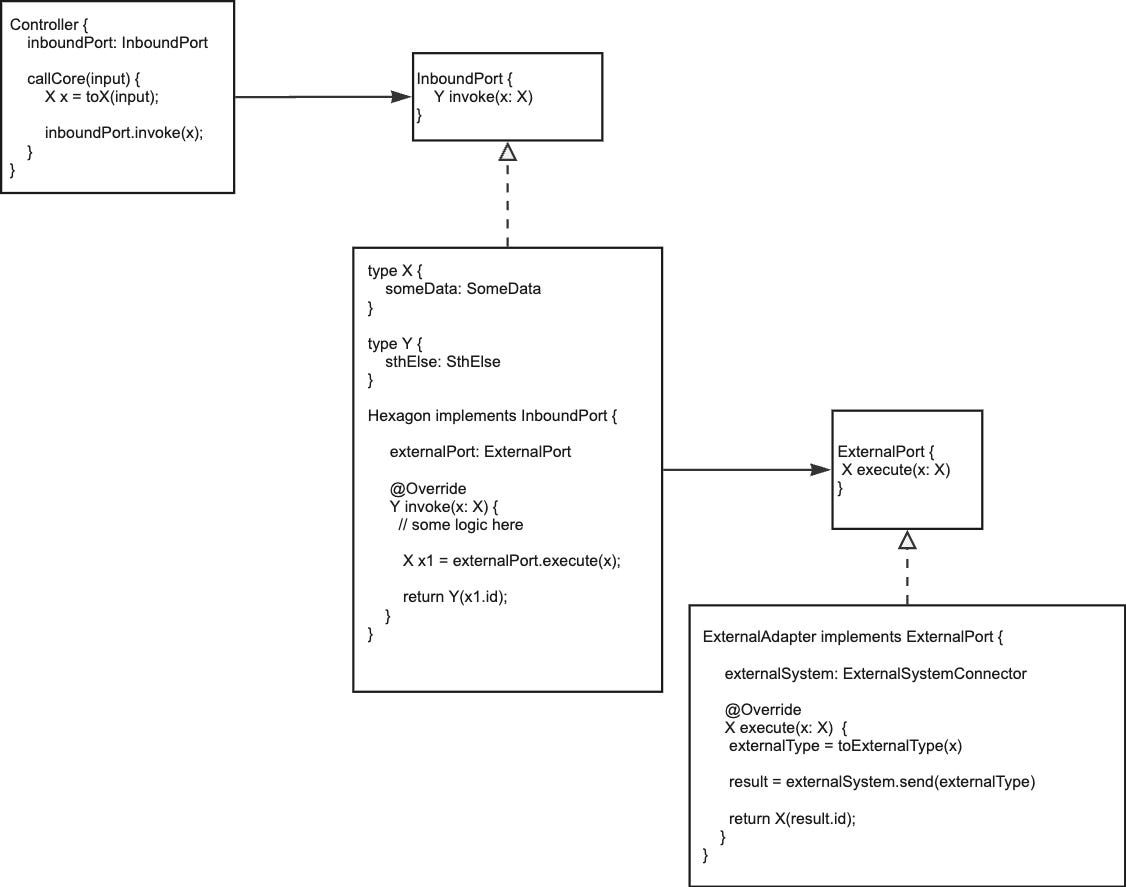
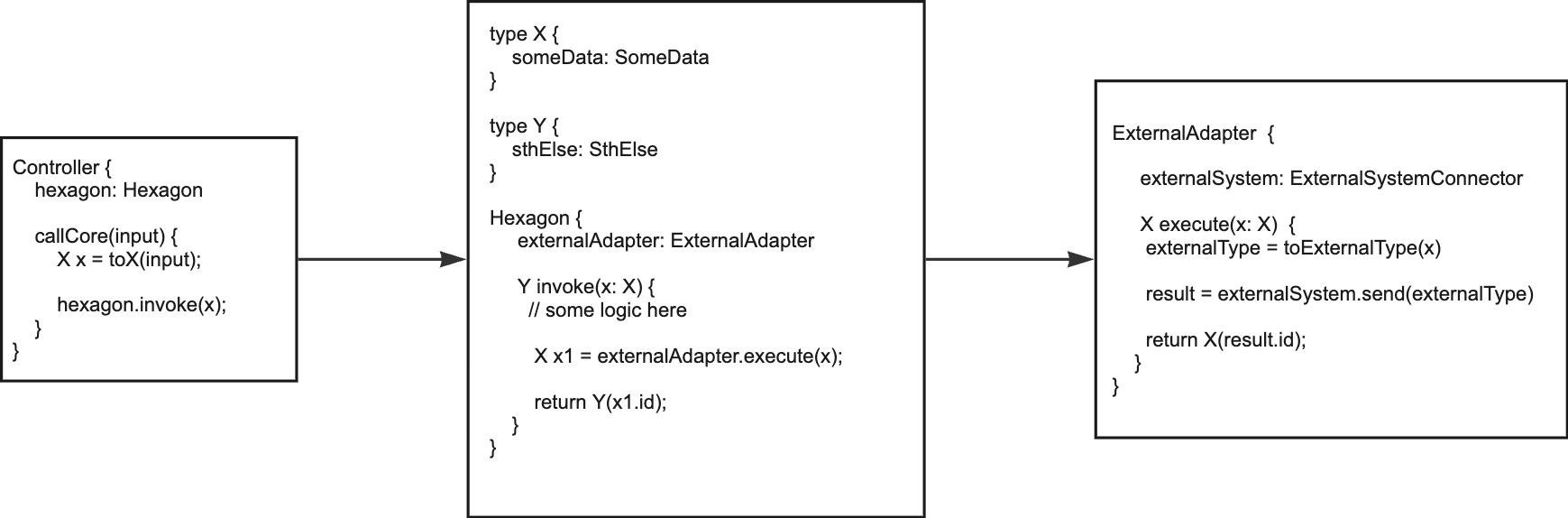
The mapping does not disappear like that, unfortunately, but at least when traversing the application, we don’t have to awkwardly jump in and out of interface definition files.
What About Inbound Ports?
In my opinion, the last port I usually introduce is that of the inbound port. In most cases, there is only one implementation of that port and should it be replaced by a test double, it can easily be achieved by existing frameworks or vanilla inheritance.
Outbound ports may be reasonable especially when we want to replace an existing with a new one without the Hexagon knowing about it - but because an interface can be extracted in a blink of an eye, we may also wait this out until the actual need arises.
Simply adhering to the dependency inversion principle also in the implementation of the outbound adapter class avoids the need to add interfaces yet.
Service? Use Case!
I often see generic service classes implementing all the inbound port interfaces. That way, all the use cases are summarised in a single service for convenience. However, this makes it hard to split out cohesive, vertical use-case slices which simplifies their discovery.
If there is one contribution of Clean Architecture that solves this problem, in my opinion, it is the Use Case granularity of the hexagon core. One use case may contain a couple of (private) methods, but only the actual use case method is invoked by a controller. This increases cohesiveness and reduces coupling from unrelated use-case methods.
Should we provide only one controller for all the publicly exposed API methods, at least we can structure the application core simply by different use case classes. We don’t even need additional folders anymore within that application folder to separate the use cases. Use cases become first class citizens in this screaming, domain-centric architecture.
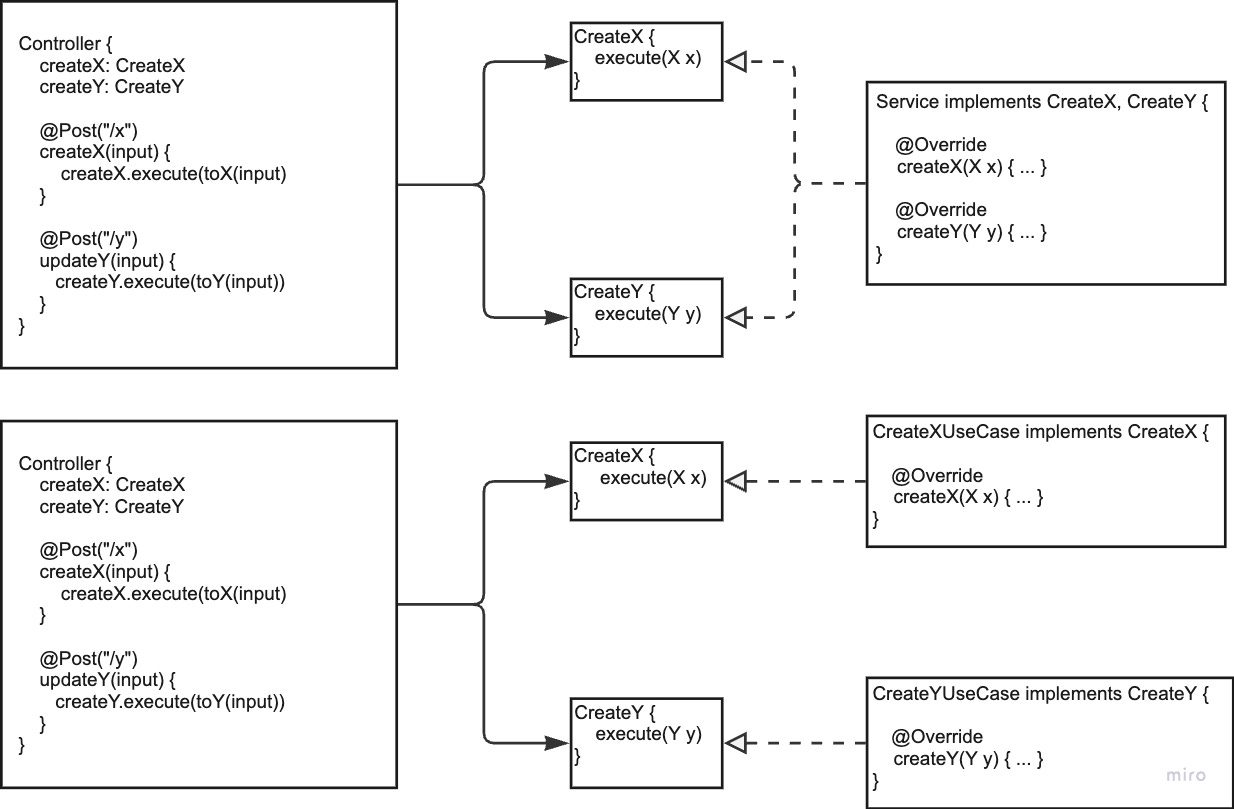
If we additionally apply the idea from before and leave the inbound ports out, the controller’s member variables basically stay as expressive as before, but navigating the code is simplified.
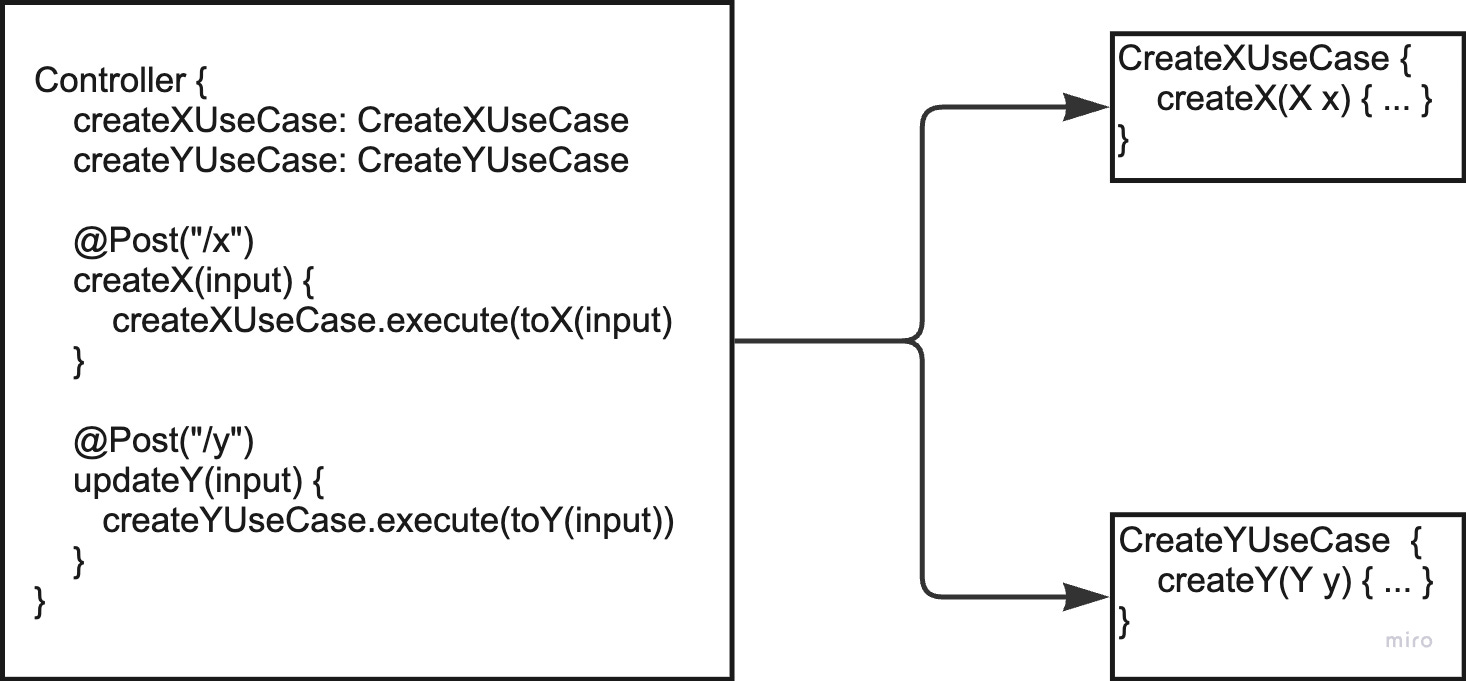
Vertical Use Case Slice?
A next natural step from the above idea is to create a controller per use case. This also makes sense from a cohesion point of view. That means the following:
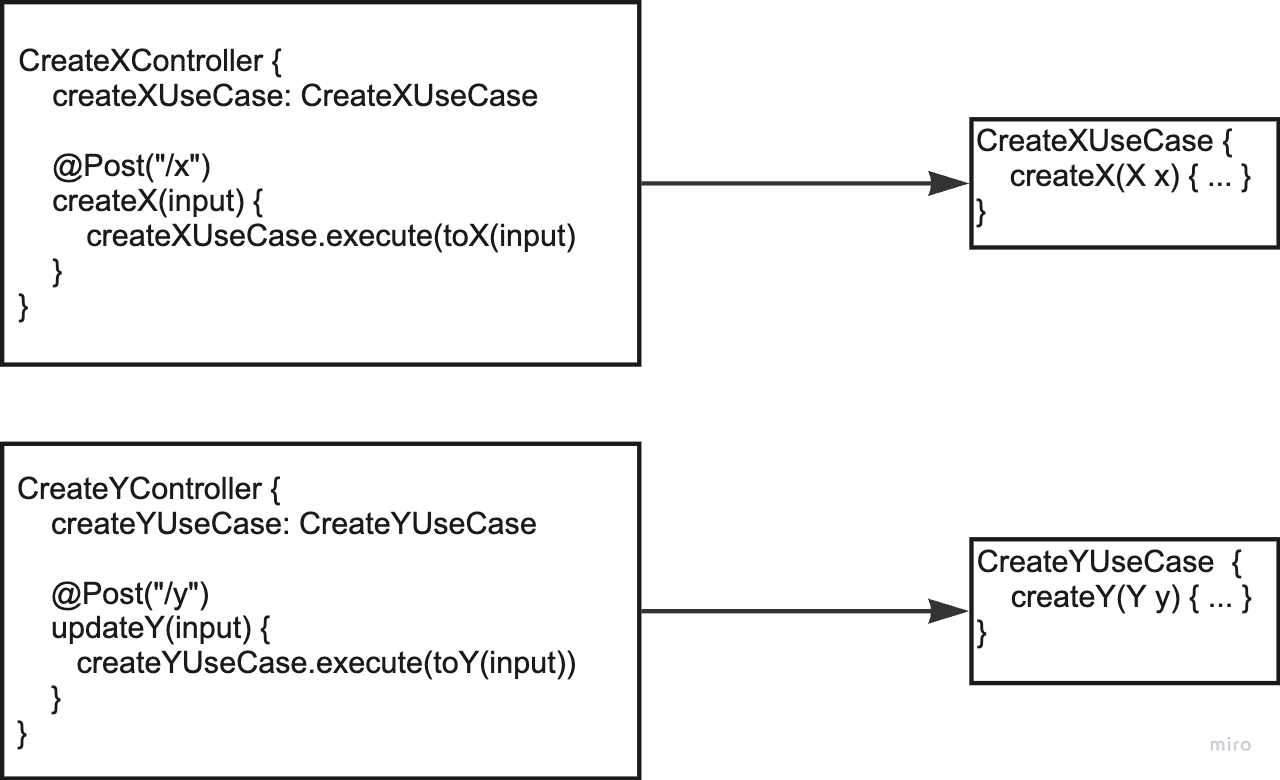
But now we have to ask ourselves what we gain from the additional abstractions if we always have a controller- and use-case pair. We are basically back to Onion Architecture’s “CustomerController”, “CustomerService”, now on a use case granularity. So naturally, we could just inline the entirety of the use case into the controller:

And inject the adapters for databases and external systems directly. And maybe even rename the controller to use case?

We may have to adjust transaction boundaries and move them from the use case method to the controller method instead. But else, there is actually nothing wrong with such a setup. We basically have arrived at a vertical-slice architecture.
Any repository or surrounding system can directly be called from the controller/use case. Because data-access classes may be used with various use cases in the same bounded context, we can add them to an external data access folder within a bounded context (or move it even outside into a shared module if other bounded contexts need to access it, too).
So the structure may look like:
app
|_ shared_data_access
|_ bounded_context_1
|_ bounded_context_2
|_ use_cases
|_ CreateXUseCase
|_ CreateYUseCase
|_ data_access
|_ ExternalSystemAdapter
|_ ExternalSystemWhich flattens the traditional modules to use cases and data access.
Dependency Inversion? Anti-Corruption!
I’d keep dependency inversion on the outbound side even if no outbound ports are employed. A simple adapter class can map between use case and external system. I feel this mapping is important to avoid coupling with an external system or database that may not be under our direct control. The adapter effectively becomes an Anti-Corruption Layer.
If the data access is under our control, we may even leave out this external system adapter and directly access the database or repository connector. In any case, I recommend to separate data-access logic from business logic even if the code remains rather procedural.
If that proofs too difficult to achieve within one team, separating the two concerns using abstractions like classes and functions with own data structures can simplify maintainability.
No Architecture At All?
Let’s face it: most of the code we create is not rocket science. We basically move data from A to B, with a bit of logic for manipulation in between. The important separation is that of the 3 concerns presentation, business logic, data access.
The data we present to the user may not be the same as the one we need for business calculations, and the data access may store different fields again for optimisation reasons. This is often true for command-like operations, meaning use cases that change a state. So having 3 different data representations may actually proof reasonable, except when we simply map the same fields between different concerns.
On the other hand, query-like operations (getters) can provide precomputed views that don’t require any mapping at all. Having additional data structures for core and adapters, where we map the same data items multiple times without any logic in between, is a maintainability nightmare. Here, PA-style architectures are simply in the way of maintainable software.
If team members have mastered this logical separation between data access, presentation, and business logic (which doesn’t take longer than a couple of weeks of active practicing), they should be able to decide on a use-case basis how much abstraction is actually needed.
A Final Word
Software Architecture, even if only used within a Modulith to structure low-level code, is still architecture. This means we need to make architectural decisions: we need to weigh pros and cons of every decision against each other with incomplete understanding and information.
This also means that we sometimes get it wrong. There is simply no silver-bullet solution template that we can apply to every software design problem, even though I feel that many software engineers want exactly that.
Instead, we need to be aware of all the possibilities we have to structure our code, be it all inlined procedural code per use case or full-blown Clean Architecture (which, in my opinion, generally will be too over-engineered), how to identify and resolve problematic software design, and how to quickly move from one design to another, either through manual refactoring or well-formed prompts if we want to give AI a shot.
This is hard. And the more we practice, the better we become. Instead of pretending we know everything, we should work together and leave our ego at the door. Every idea and decision has pros and cons, and some may be better suited than others. But most ideas are not absolutely wrong.
If the software works according to specification or user feedback and is simple to change with no to few bugs, the design is the right one, regardless of how much Ports & Adapters was applied or not.
We need to judge design according to our ability to create, change and maintain it cheaply, not on “how it looks like”. Only then will we create software that actually solves the problem of their users. And only then will they come back to us and ask for more.
Want to learn more?
Curious to go deeper?
Our O’Reilly course “DDD, EventStorming, and Clean Architecture” covers in detail how to get from a Layered- to Hexagonal-, Clean-, and even Vertical-Slice Architecture and the pro’s and con’s of each approach.
This overview will equip you with the theoretical and practical knowledge needed to guide your AI assistant into the right direction during development and avoids creating a procedural mess in the process!
We also provide remote, hybrid, and on-site workshops on Software Design and Architectural Design Patterns like Hexagonal- and Vertical-Slice Architecture which you can find on our website - codeartify.com.
Check it out!
The pragmatism angle is spot on. I've found the port interface pays for itself almost immediately when you're dealing with external vendors though. In Laravel the Illuminate\Contracts namespace is basically a port layer, and every time you swap a MAIL_MAILER or QUEUE_CONNECTION in .env you're swapping an adapter without touching domain code. The ceremony is minimal but the freedom to switch providers is real. Covered this with payment gateway, search, and SMS examples here: https://reading.sh/the-architecture-pattern-that-makes-vendor-lock-in-optional-48e485cb4f03?sk=6928cb411cc2400f69ddb85023cf1f7f